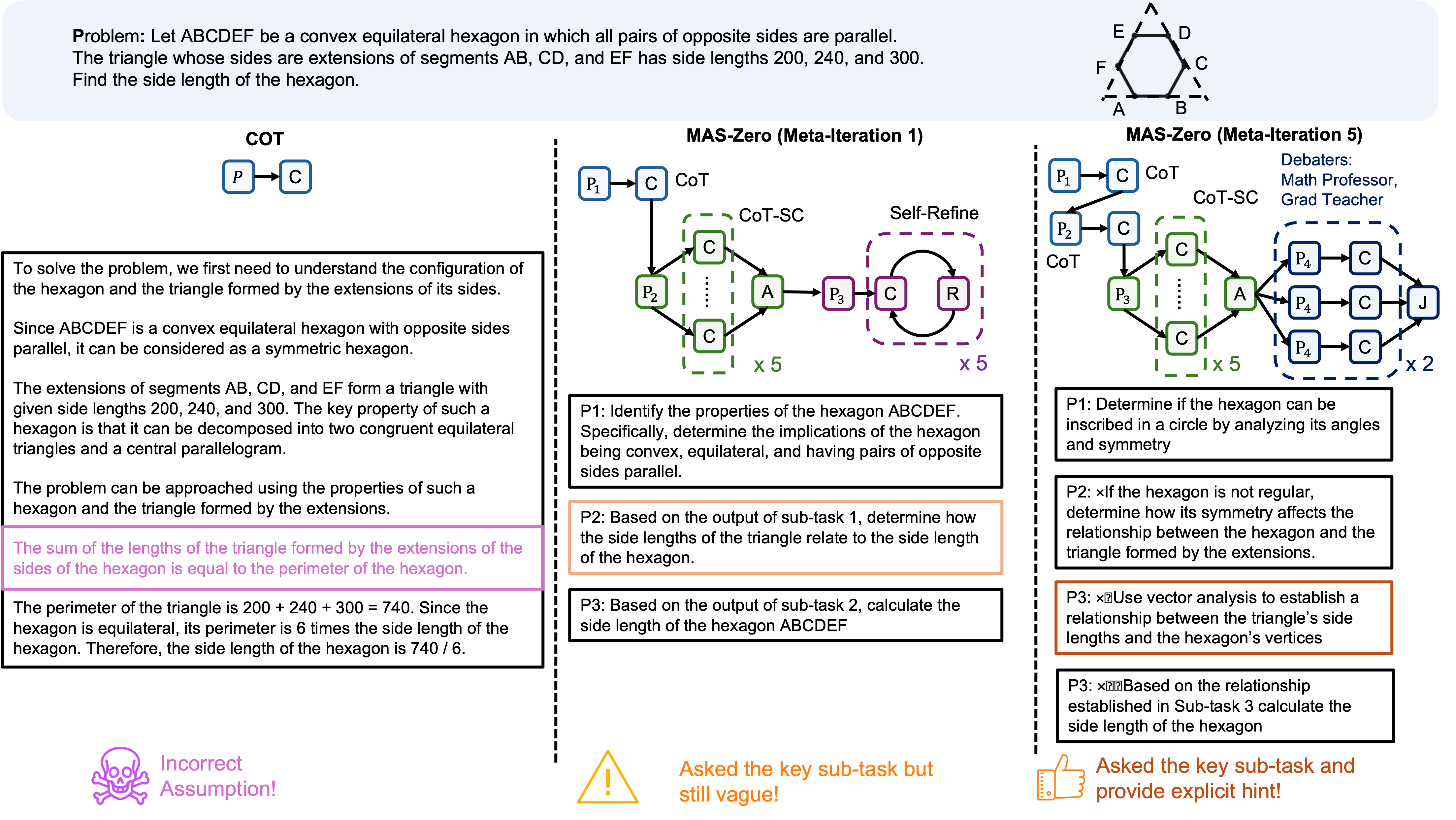
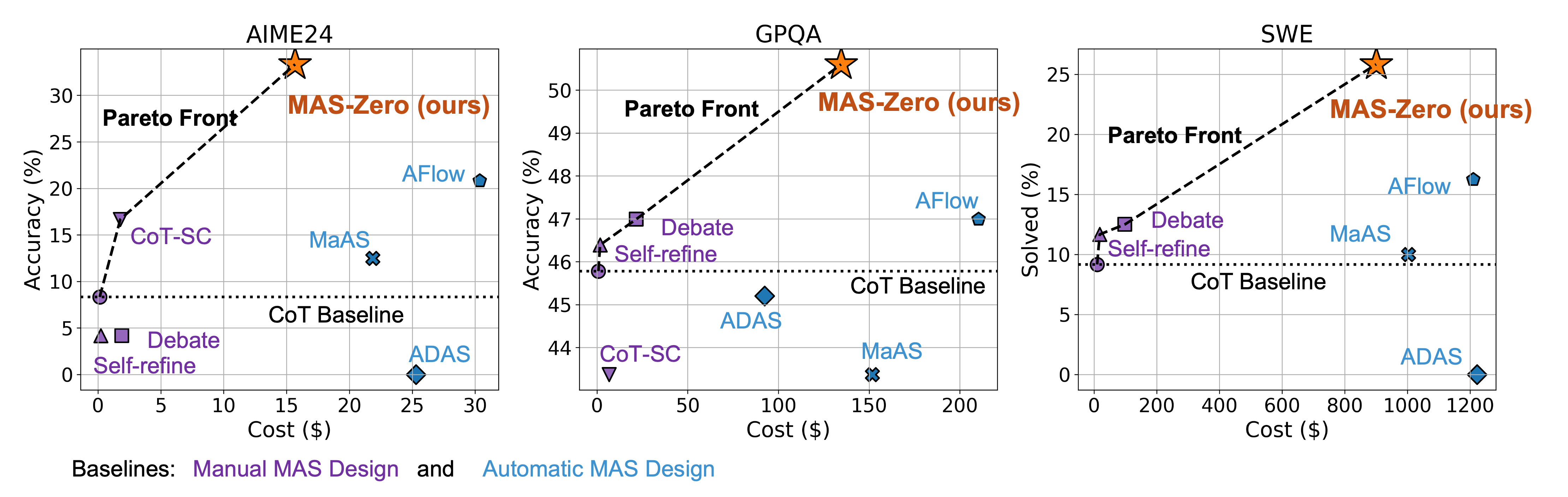
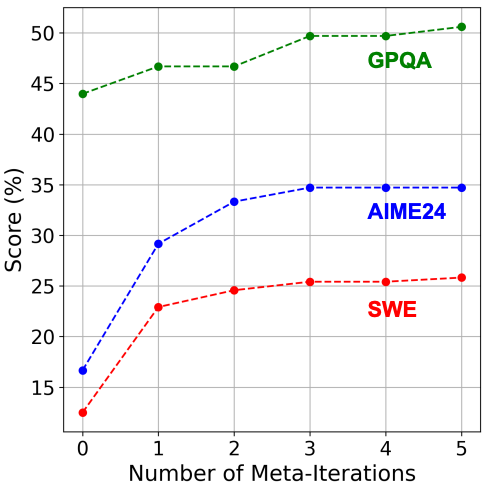
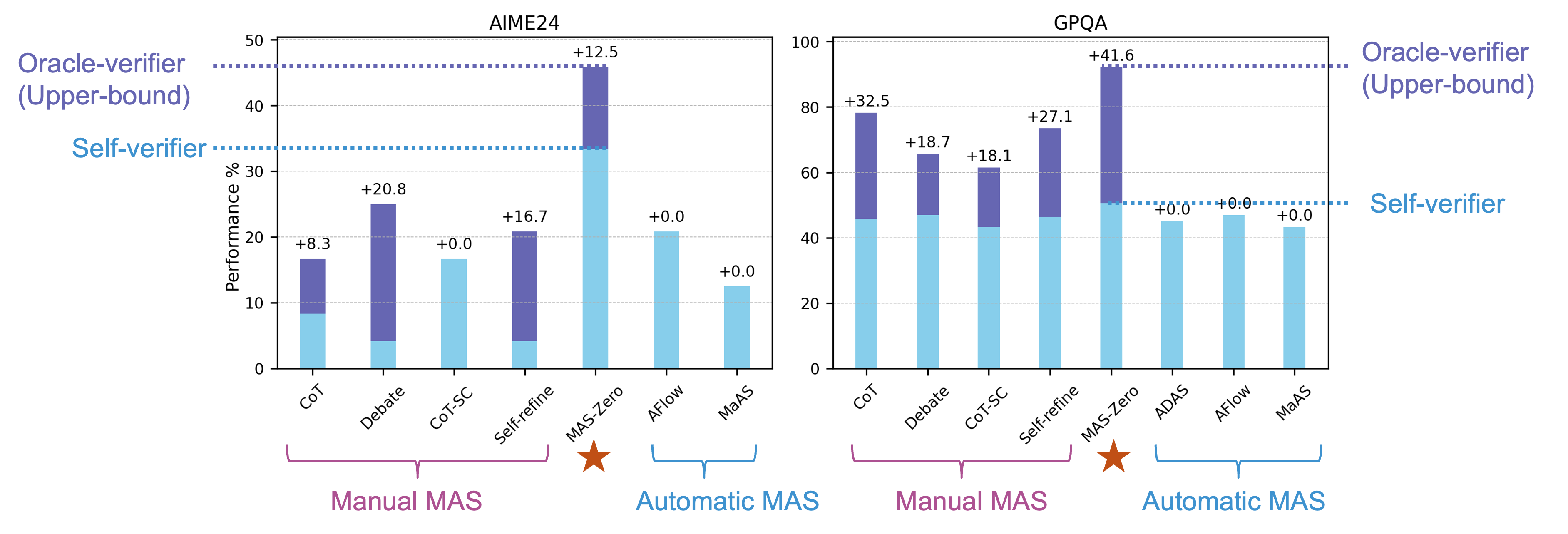
MAS-Zero
Designing Multi-Agent Systems with Zero Supervision
The first inference-time-only framework that meta-designs agent teams through self-evolved planning, feedback, and verification loops.
📍 Lightning talk - Salesforce Booth #1129
Wed Dec. 3, 4:20–4:45 PM PST · San Diego Convention Center
📍 Lightning talk - SEA Workshop
Sun Dec. 7, Upper Level Room 23ABC · San Diego Convention Center






Salesforce AI Research